show databases like 'alpha%'; -- 以alpha开头
show databases like '%beta'; -- 以beta结尾
show databases like '%gamma%' -- gamma出现在任何位置
-- 其中单引号''也可以替换为双引号"",但是注意使用英文
—
-- 查看创建数据库命令(指定的数据库使用什么SQL语句创建出来的)
show create database <数据库名称>;
-- 举例
-- 想找id为1的
select * from student_t where id=1;
-- chinese 大于90的
select * from student_t where chinese > 90;
-- 想找到id大于10的
select id, name from student_t where id > 10;
使用 WHERE 关键字并指定查询条件|表达式, 从数据表中获得满足条件的数据内容.
在构建Where的查询条件|表达式的过程中, 我们可能需要了解到一些重要的SQL运算符
在where语句的后面,我们可以用到算数运算符。也可以用到逻辑运算符。
在查询结果中,我们也可以使用算术运算符。
算术运算符
运算符
作用
+
加
–
减
*
乘
/
除
%
取余
-- 算数运算符,不仅可以出现在where中,还可以出现在查询列中。
-- 语数外总分 小于180的
-- 语文-数学 分差大于30的
-- 加权平均,按语文0.5 英语0.1 数学0.4求加权平均分
-- 加权平均分,小于等于60的
-- 求每个人的平均分,语数外三科
-- 求每个人的平均分,只筛选出平均分小于60的
-- 找出id是奇数的
-- 找语文成绩是偶数的
-- eg:
-- 语数外总分 小于180的
select * from student_t where (chinese + english + math) < 180;
-- 语文和数学 分差大于30的
select * from student_t where (chinese - math) > 30;
-- 加权平均,按语文0.5 英语0.1 数学0.4求加权平均分
select *, (chinese*0.5 + english*0.1 + math *0.4) from student_t;
-- 加权平均分,小于等于60的
select *, (chinese*0.5 + english*0.1 + math *0.4) from student_t where (chinese*0.5 + english*0.1 + math *0.4) <= 60 ;
-- 求每个人的平均分。语数外
select *, (chinese + english + math) / 3 from student_t ;
-- 求每个人的平均分,只筛选出平均分小于60的
select *, (chinese + english + math) / 3 from student_t where (chinese + english + math) /3 < 60;
-- 找出id是奇数的
SELECT * FROM student_t WHERE id % 2 = 1;
-- 找语文成绩是偶数的
SELECT * FROM student_t WHERE chinese % 2 = 0;
比较和逻辑运算符
运算符
作用
运算符
作用
=
等于
<=>
等于(可比较null)
!=
不等于
<>
不等于
<
小于
>
大于
<=
小于等于
>=
大于等于
between and
在闭区间内
like
通配符匹配(%:通配, _占位)
is null
是否为null
is not null
是否不为null
in
在列表内
not in
不在列表内
and
与
&&
与
or
或
\
\
或
需要注意的:
=无法判断null。一般使用 is null来单独处理null
like中,%表示通配,_表示占位。 一个_代表一个字符。
-- 查询语数外总成绩大于 180 的同学信息;
select *,(chinese + english + math) from student_t where (chinese + english + math) > 180;
-- 查询数学成绩在[80,90]区间的同学姓名;
select * from student_t where math between 80 and 90;
select * from student_t where math >= 80 and math <=90;
-- 查询各科都及格的同学姓名;
select * from student_t where chinese >= 60 and math >= 60 and english >= 60;
-- 查询各科只要有一科及格的同学姓名;
select * from student_t where chinese >= 60 or math >= 60 or english >= 60;
select * from student_t where id=6;
-- 查询一班和二班的同学信息;
select * from student_t where class = '一班' or class = '二班';
select * from student_t where class in ("一班", "二班");
-- 查询姓贾的同学(只要姓贾就行)
SELECT * FROM `student` where name like '贾%';
-- 查询姓贾的同学,两个字的
SELECT * FROM `student` where name like '贾_';
-- 查询语文分数在 60 或90的同学
SELECT * FROM `student` where chinese in (60,90);
distinct => 去重
获取某个列的不重复值。或者是某些列的不重复值
SELECT DISTINCT <字段名> FROM <表名>;
使用DISTINCT对数据表中一个或多个字段重复的数据进行过滤,重复的数据只返回其一条数据给用户.
什么叫重复:就是多个列,全部相等,这时候就认为是重复的数据。
-- 返回所有的 class
select class from student_t;
-- 返回不重复的 class
select distinct class from student_t;
-- 返回所有去重后的英语成绩
-- 6条
select distinct english from student_t;
-- 返回两列 英语和数学去重后的结果。
-- 10条
select distinct english,math from student_t;
-- 13条
-- 90.90 重复了一条
-- 90,80 重复了两条
select english,math from student_t;
limit => 限制结果集
一般用来做,比如限制最大的返回数目。或者是做分页上面。
select * from student_t limit 10;
SELECT <查询内容|列等> FROM <表名字> LIMIT 记录数目;
SELECT <查询内容|列等> FROM <表名字> LIMIT 初始位置,记录数目;
SELECT <查询内容|列等> FROM <表名字> LIMIT 记录数目 OFFSET 初始位置;
eg:
-- 限制数目 为number个
-- 限制最大返回number个,如果表中记录不足number个,只会返回表中的记录数。
select * from <表名> where condition limit [限制量];
-- 偏移量为offsetNumber 从0开始
select * from <表名> where condition limit [偏移量], [限制量];
-- 偏移量offsetNumber
select * from tableName where condition limit number offset offsetNumber;
-- 可以为取出来的列名 取一个别名
select id,name as student_name,class from student_t;
-- 可以为一些计算的属性取别名
select (chinese + english + math) as total_score from student_t;
-- 也可以为表名取别名
select s.name from student_t as s;
select s.name from student_t s;
-- as 可以省略
as给字段名取别名其实是为了修改结果集中的列名 → 在后面JDBC内容中也会使用到
as给表名取别名在后面多表查询中会使用,主要是为了写SQL的时候偷懒
简而言之,主要场景是多表查询
order by => 排序
比如我们想根据id进行排序; 或者想根据年龄进行排序。
SELECT <查询内容|列等> FROM <表名字> ORDER BY <字段名> [ASC|DESC];
SELECT <查询内容|列等> FROM <表名字> GROUP BY <字段名...>
eg:
select class from student_t group by class;
select class,chinese from student_t group by class, chinese;
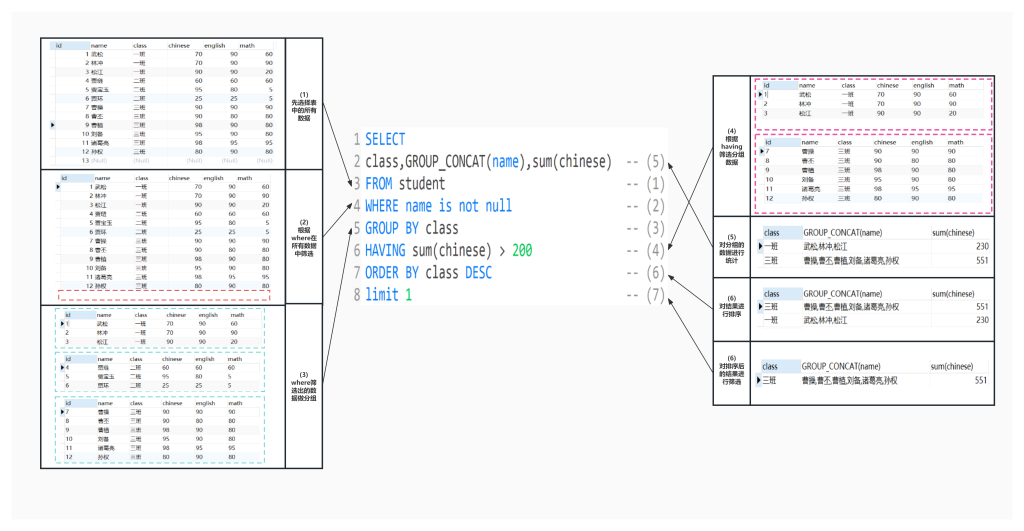
select class, group_concat(name), group_concat(chinese) from student_t group by class;
-- 获取语文成绩大于90分的,按照班级分组
select class, group_concat(name) from student_t where chinese > 90 group by class;
-- 获取班级的平均分
select class, group_concat(name), avg(chinese) from student_t group by class;
-- 获取班级人数大于三个人的班级
select class, group_concat(name) from student_t group by class having count(*) > 3;
-- 获取班级平均语文成绩大于60分的
select class, group_concat(name), avg(chinese) from student_t group by class having avg(chinese) > 60;
GROUP_CONCAT()函数会把每个分组的字段值都拼接显示出来.
HAVING 可以让我们对分组后的各组数据过滤。(一般和分组+聚合函数配合使用)
having注意和where的区别
where主要用于对原始表进行过滤。having是对group by 后的结果进行过滤,一般配合聚合函数一起使用。
注意点:
group by的select列中,只能有两种,1.在group中出现的字段,2.聚合函数聚合起来的东西
多个字段分组查询时,会先按照第一个字段进行分组。如果第一个字段中有相同的值,MySQL 才会按照第二个字段进行分组。如果第一个字段中的数据都是唯一的,那么 MySQL 将不再对第二个字段进行分组.
如果在select 字段中,可以看出group 字段,后方可以使用数字代替,从1开始
-- 会报错。如果有同学不报错,是因为有一个选项没开
-- select * from student_t group by class;
-- select id,class from student_t group by class;
-- 在select中出现的,只能有 group by 后的字段;或者是聚合函数聚合起来的东西
select class from student_t group by class;
-- 根据英语成绩进行分组
select english from student_t group by 1;
-- 根据英语成绩,数学成绩进行分组
-- 会先按照英语成绩分组,如果英语成绩相同,则按照数学成绩进行分组
select english,math from student_t group by english,math;
聚合函数
聚合函数一般用来计算列相关的指定值. 通常和聚合一起使用
函数
作用
函数
作用
COUNT
计数
SUM
和
AVG
平均值
MAX
最大值
MIN
最小值
SELECT <查询内容>|列等 , (聚合函数)|* FROM <表名字> GROUP BY <列等> HAVING (聚合函数)条件 |条件;
其中HAVING是用来做拼接聚合值条件
COUNT: 计数
select count(<列>) from tableName [where 条件];
-- eg:
select count(*) from student_t;
select count(name) from student_t;
-- 和分组一起使用。查看每个班级有多少人数
select class,count(*) from student_tgroup by class;
COUNT(*):表示表中总行数
COUNT(列): 计算非NULL的总行数。统计这个组,这一列非null的总行数。
SUM: 求和
SELECT <查询内容>|列等 , SUM<列> FROM <表名字> GROUP BY <列等> HAVING SUM<表达式>|条件
-- eg:
select sum(chinese) from student_t;
select sum(chinese), sum(english), sum(math) from student_t;
-- 查看每个班级的语文总分
select class,sum(chinese),group_concat(chinese) from student_tgroup by class;
AVG: 平均值
SELECT <查询内容>|列等 , AVG<列> FROM <表名字> GROUP BY <列等> HAVING AVG<表达式>|条件
-- eg:
select avg(chinese) from student_t;
select avg(chinese), avg(english), avg(math) from student_t;
-- 按班级查看平均分
select class,avg(chinese), avg(english), avg(math) from student_tgroup by 1;
MAX: 最大值
SELECT <查询内容>|列等 , MAX(<列>) FROM <表名字> GROUP BY <列等> HAVING MAX(<表达式>)|条件
-- eg:
select max(chinese) from student_t;
select max(chinese), max(english), max(math) from student_t;
MIN: 最小值
SELECT <查询内容>|列等 , MIN(<列>) FROM <表名字> GROUP BY <列等> HAVING MIN(<表达式>)|条件
-- eg: select min(chinese) from student_t; select min(chinese), min(english), max(math) from student_t;
-- 查询每个同学的总成绩,平均成绩,并用别名表示; -- ROUND(100.3465,2) 四舍五入 select name, (chinese + english + math) as total_score, ((chinese + english + math)/3) as avg_score from student_t;
select name, (chinese + math + english) as total_score , round((chinese+math+english) /3, 2) as avg_score from student_t;
-- 查询数学最大值,并用别名表示; select max(math) as max_math_score from student_t;
-- 查询外语最小值,并用别名表示; select min(english) as min_english_score from student_t;
-- 查询全体学生的语数外各科平均成绩,并用别名表示; select avg(chinese),avg(math),avg(english) as avg_english from student_t;
增加上Having对聚合结果进行筛选
SELECT <查询内容>|列等 , (聚合函数)|* FROM <表名字> GROUP BY <列等> HAVING (聚合函数)条件 |条件;
-- eg:
select class, group_concat(name), count(*) from student_t group by class;
select class, group_concat(name), count(*) from student_t group by class having count(*) > 3;
-- 获取语文成绩大于90分的,按照班级分组
-- 获取班级的平均分
-- 获取班级人数大于三个人的班级
-- 获取班级平均语文成绩大于60分的
-- 查询班级语文总分大于200的班级(可以显示一下语文总分)
-- 查询班级平均分,学生的限制:数学大于等于60,语文大于等于60的
-- 查询班级情况,要求学生语文最大的大于等于90,语文最少分大于等于70
-- 查询班级,语文最小成绩大于等于60,数学也是
select class from student_t group by class having sum(chinese) > 200;
SQL执行顺序
(5) SELECT <列名>, ...
(1) FROM <表名>, ...
(2) [WHERE ...]
(3) [GROUP BY ...]
(4) [HAVING ...]
(6) [ORDER BY ...];
(7) [Limit ...]
-- 如果这个表存在 就删除
drop table if exists user;
create table user(
id int primary key auto_increment,
name varchar(255),
password varchar(255)
);
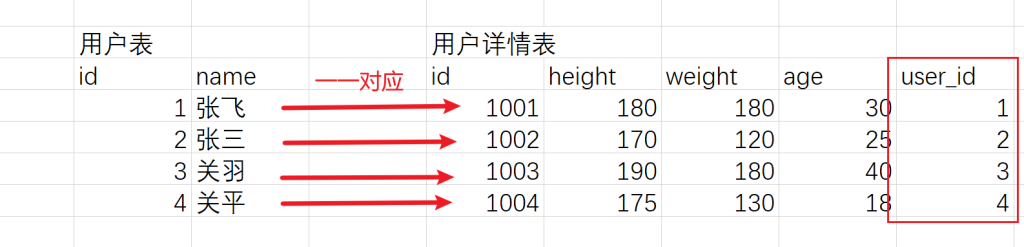
drop table if exists user_detail;
create table user_detail(
id int primary key auto_increment,
user_id int,
address varchar(255),
pic varchar(255)
);
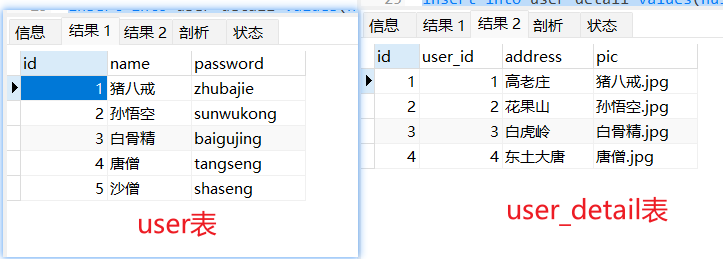
insert into user values (1, "猪八戒", "zhubajie");
insert into user values (2, "孙悟空", "sunwukong");
insert into user values (3, "白骨精", "baigujing");
insert into user values (4, "唐僧", "tangseng");
insert into user values (5, "沙僧", "shaseng");
select * from user;
insert into user_detail values(null, 1, "高老庄", "猪八戒.jpg");
insert into user_detail values(null, 2, "花果山", "孙悟空.jpg");
insert into user_detail values(null, 3, "白虎岭", "白骨精.jpg");
insert into user_detail values(null, 4, "东土大唐", "唐僧.jpg");
select * from user_detail;
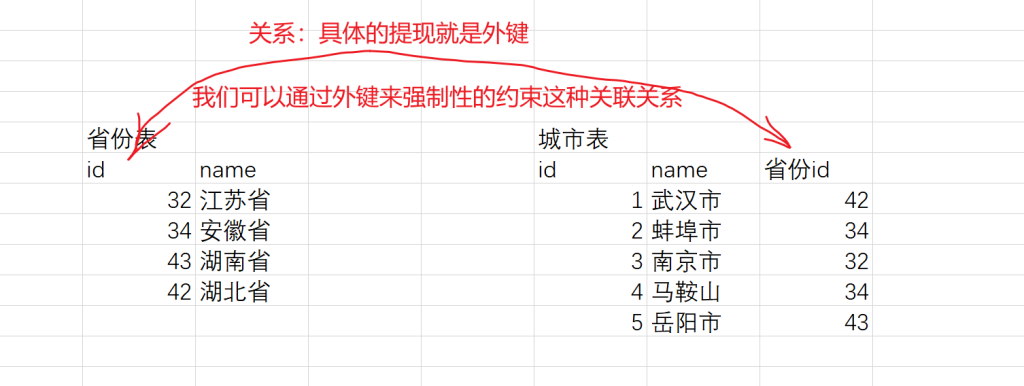
交叉连接
交叉连接其实就是求多个表的笛卡尔积。
-- 交叉连接
select * from user cross join user_detail;
-- 现在想找有哪些同学学了Java。
-- 首先先拿到Java的id
select id from tec_cource where name='Java'; -- 1
-- 然后再把这个id=1 放给第二个
select * from tec_sele_cource where cource_id=1; -- 1,3
select * from tec_stu where id in (1,3);
-- 看学生信息
select * from tec_stu where id in (
-- 看哪些学生选了 Java
select student_id from tec_sele_cource where cource_id=(
-- 获取Java的id
select id from tec_cource where name='Java'
)
)
不建议大家用。效率差。因为每一层查询会生成临时表
联合查询(了解)
SQL支持把多个SQL语句的结果拼装起来。
-- 写了两个SQL。把两个SQL的结果拼接起来
select * from student_t where class = '一班'
union
select * from student_t where class = '二班';
-- union要求返回的列数目要一致
-- 我们可以使用union关键字对SQL1和SQL2的结果去做并集,一般来说联合查询作用不大
select * from student_t where class in ('一班','二班');
-- 当上面这个SQL语句查询速度很慢的时候,可以考虑union联合查询来提高效率。
-- union all 会把sql的结果,直接拼接起来。
select * from student_t where class = '一班'
union all
select * from student_t where class = '二班';