现在假设我们有如下的一张数据库表

现在假设我们有一个需求是从这张表中搜索“手机”或者“华为手机”的相关信息,我们会怎么做?
select * from product where name like "%手机%";
select * from product where name like "%华为手机%";但是针对这张表,我们如果直接通过以上SQL语句来查询,会存在两个问题:
- 针对单表的全表扫描效率低
- 关系数据库中提供的查询功能弱
思考一下,我们的一个电商网站中,有上百万商品数据,如果我们采用like的方式,去实现商品搜索的功能,其效率是非常低下的,同时由于用户输入的商品关键字是比较随意的,使用like的方式往往也很难真正查询到用户想要的商品。
ES介绍及基本概念
在很多场景下,比如电商网站的商品搜索,我们都需要使用全文检索的功能查询所需的内容,那么如何高效的实现全文检索的功能呢?解决之道就在于Elastic Search:
ElasticSearch是一个基于Lucene的分布式、高扩展、高实时的基于RESTful 风格API的搜索与数据分析引擎
为什么Elastic Search能够实现大规模数据场景下的高效全文检索呢?主要是因为在ES中,数据的存储和组织方式与关系数据库不同。
我们首先需要了解ES中的基本概念:
- 字段(Field): 一个字段表示一个属性,类比于数据库表中的属性,数据库中的一行数据通常是多个属性值组成
- 文档(document):在ES中数据的存储和关系数据库不同,所有的数据都是以文档的JSON document的形式存在,document是ES中索引和搜索的最小的数据单位,类比于数据库中的一行数据,通常有多个字段值组成
- 映射(mapping): mapping定义了document中每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。
- 索引(index): ElasticSearch存储数据的地方,可以理解成关系型数据库中的数据库概念,存放一类相同或者类似的document,比如一个员工索引,商品索引。
- 类型(Type):逻辑上的数据分类,一种type就像一张表。如用户表、角色表等。在Elasticsearch6.X默认type为_doc,es 7.x中删除了type的概念
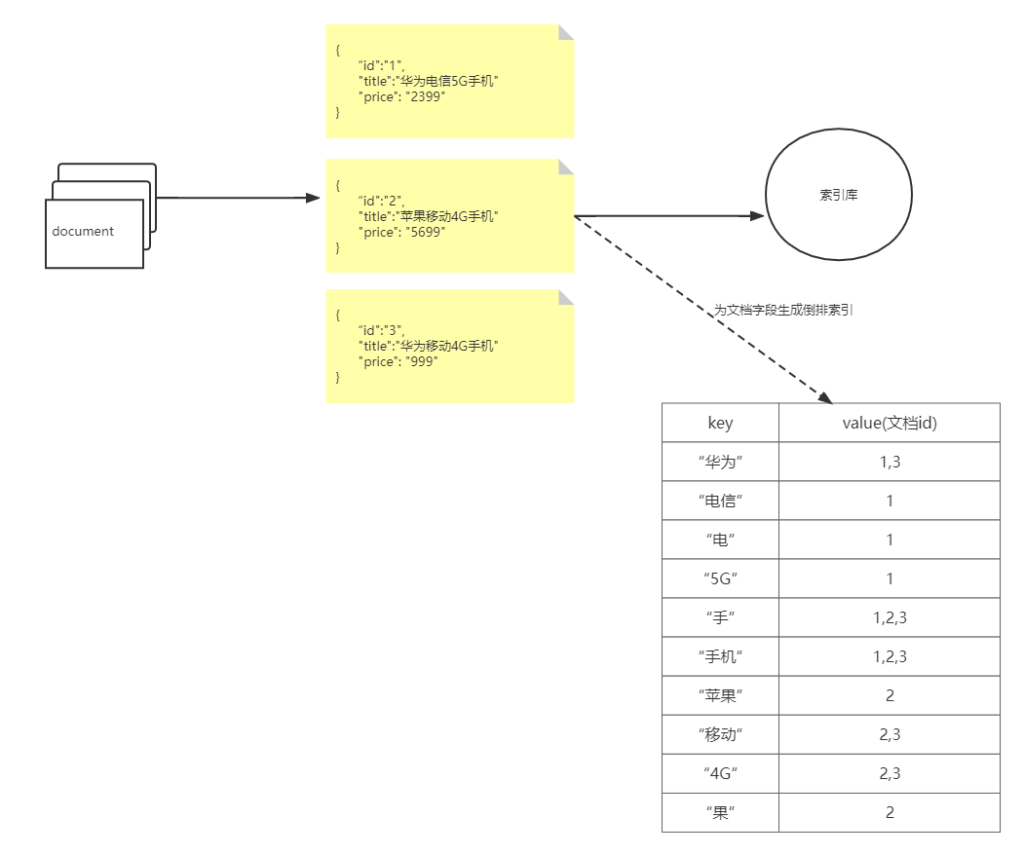
在了解了ES的基本概念之后,接下来,我们可以大致解释下,为何ES可以实现高效的全文检索功能,其中一个很重要的原因是ES使用了倒排索引(这里要注意的一点是,倒排索引和文档的存储本身没有关系,只是为了快速的全文检索,针对document的一个或者多个字段,所创建的索引)
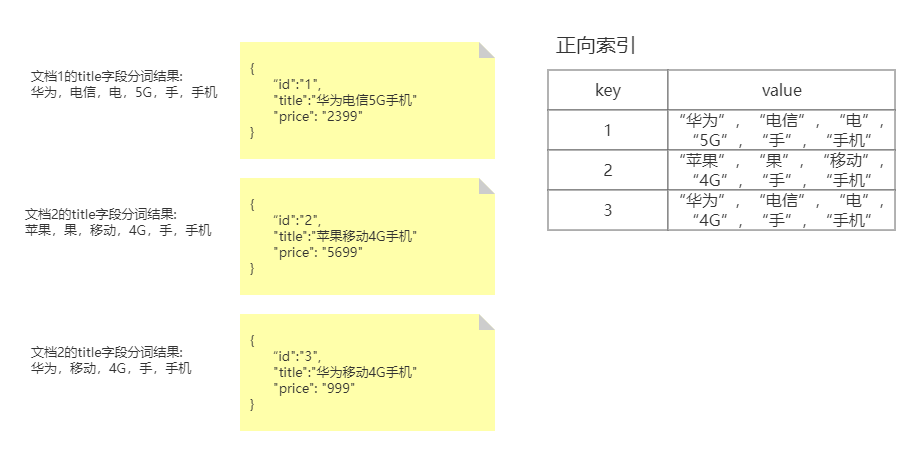
那么什么是倒排索引呢?为了理解什么是倒排索引,我们先来理解正排索引。针对以下3条document文档数据所创建的正排索引如下:
关键词: 华为手机 ——> 华为 手机
- 凡是索引其本质都是在建立一种映射关系
- 无论是正排索引还是倒排索引,在创建索引时都是要对目标字段的值进行分词的。
- 正排索引,建立的是文档的唯一标识Id(内容所在位置) ——> 文档目标字段内容的映射
如果我们是基于正向索引来查找和“华为手机”相关的商品信息(根据商品的title字段的值来匹配),首先对搜索的关键字也会做分词处理,比如分解为”华为”和”手机”两个关键词,然后遍历,每一个文档,和将关键词和文档中的分词内容进行匹配,此时,我们可以查找到我们所需要的华为手机的相关商品信息。
但是,使用正向索引我们仍然无法避免,遍历每一个商品对应的文档(“类似全表扫描”),这种匹配方式,效率比较低下。接下来,我们换种方式,基于倒排索引,来实现搜索。
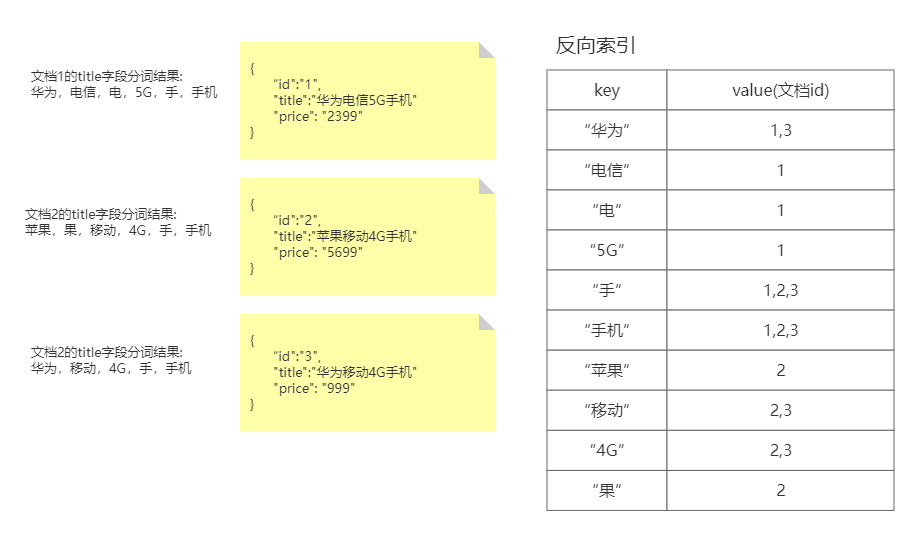
- 反向索引是以文段目标字段所有可能的分词结果为key,其value表达的是包含改词的文档Id(即文档位置)
- 通过对比可知,反向索引表达的是文档字段内容 ——> 包含该内容的文档位置(文档Id)的映射
如果我们,基于倒排索引,来查找和关键字“华为手机”相关的商品,那么很显然,我们很容易就可以查询出想要的结果,并且还不需要,遍历每一个商品信息。同理,ES在搜索时就是基于倒排索引,所以它的搜索性能很好。
ES及可视化客户端安装
详情参见项目介绍中的环境搭建
Restful API操作ES
ES虽然是基于Java语言开发的,但它的使用却不仅仅局限于Java语言,因为ES对外提供了Restful风格的API,我们可以通过这些Restful风格的API向ES发送请求,从而操作ES。
操作索引
- 创建索引
PUT http://ip:端口/索引名称- 查询索引
GET http://ip:端口/索引名称 # 查询单个索引信息
GET http://ip:端口/索引名称1,索引名称2... # 查询多个索引信息
GET http://ip:端口/_all # 查询所有索引信息- 删除索引
DELETE http://ip:端口/索引名称•关闭、打开索引
POST http://ip:端口/索引名称/_close
POST http://ip:端口/索引名称/_open数据类型
简单数据类型
我们先来看一个简单的映射定义:
PUT teacher/_mapping
{
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"isMale": {
"type": "boolean"
}
}
}在定义映射的时候,类比于定义数据库中的表结构,我们需要指明每一个字段的名称,数据类型等等信息,所以我们先得了解映射中包含的数据类型。
- 字符串
text:会分词,不支持聚合
keyword:不会分词,将全部内容作为一个词条,支持聚合- 数值:long, integer, short, byte, double, float, half_float, scaled_float
- 布尔:boolean
- 二进制:binary
- 范围类型
integer_range, float_range, long_range, double_range, date_range - 日期:date
复杂数据类型
•数组:[ ] 没有专门的数组类型,ES会自动处理数组类型数据
•对象:{ } Object: object(for single JSON objects 单个JSON对象)
操作映射
- 添加映射
#添加映射
PUT student/_mapping
{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}
#查询映射
GET studnt/_mapping- 创建索引并添加映射
#创建索引并添加映射
PUT teacher
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
# 查询映射
GET teacher/_mapping- 添加字段
#添加字段
PUT teacher/_mapping
{
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
# 查询映射
GET teacher/_mapping操作文档
•添加文档,指定id
POST teacher/_doc/2
{
"name":"张三",
"age":18,
"address":"北京"
}
GET /teacher/_doc/2
•添加文档,不指定id
#添加文档,不指定id,自动生成
POST teacher/_doc/
{
"name":"张三",
"age":18,
"address":"北京"
}
#查询所有文档
GET /teacher/_search- 修改文档(可以只修改部分)
POST teacher/_update/2
{
"doc": {
"name": "李四"
}
}- 删除文档
#删除指定id文档
DELETE teacher/_doc/1分词器
对于Elastic Search而言,在生成倒排索引时,需要对文档字段分词,在搜索时,还需要对搜索关键字进行分词,分词的工作是由分词器来完成的,但是很遗憾,ES中默认使用的分词器,对中文支持的并不好,会对中文逐字拆分。所以对于中文内容的分词,我们通常会采用,对中文支持比较好的IK分词器。
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包,基于Maven构建,具有60万字/秒的高速处理能力,并且支持用户词典扩展定义。
IK分词器的使用
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“好好学习, 天天向上”拆分为“好好学习,好好学、好好、好学、学习、天天向上、天天,向上。
#方式一ik_max_word
GET _analyze
{
"analyzer": "ik_max_word",
"text": "好好学习, 天天向上"
}ik_max_word分词器执行如下:
{
"tokens" : [
{
"token" : "好好学习",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "好好学",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "好好",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "好学",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "学习",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "天天向上",
"start_offset" : 6,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "天天",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "向上",
"start_offset" : 8,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 7
}
]
}
2、ik_smart
会做最粗粒度的拆分,比如会将“好好学习, 天天向上”拆分为好好学习、天天向上。
#方式二ik_smart
GET _analyze
{
"analyzer": "ik_smart",
"text": "好好学习, 天天向上"
}ik_smart分词器执行如下:
{
"tokens" : [
{
"token" : "好好学习",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "天天向上",
"start_offset" : 5,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 1
}
]
}指定分词器查询文档
文档的查询可以分为两种查询方式: 华为手机
•词条查询(term):词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索
•全文查询(match):全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
准备工作如下:
- 创建索引,添加映射,并指定分词器为ik分词器
PUT member
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}- 添加文档
POST member/_doc/1
{
"name":"zs",
"age":18,
"address":"武汉市洪山区"
}
POST member/_doc/2
{
"name":"lisi",
"age":18,
"address":"武汉市"
}
POST /member/_doc/3
{
"name":"ww",
"age":18,
"address":"武汉黄陂"
}
- 查询映射
GET member/_search4.查看分词效果
GET _analyze
{
"analyzer": "ik_max_word",
"text": "武汉市洪山区"
}
下面分别采用两种方式查询,分词都是用IK分词器:
- 词条查询(term):只会把查询的关键字当做一个词查询
查询member中匹配到”武汉”两字的词条
GET member/_search
{
"query": {
"term": {
"address": {
"value": "武汉市"
}
}
}
}- 全文查询(match):会对查询的关键字分词
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
GET member/_search
{
"query": {
"match": {
"address":"武汉黄陂"
}
}
}Java 操作ES
我们仍然基于SpringBoot工程,首先引入依赖
<!-- Elasticsearch 8 Java API Client -->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.15.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>定义ES配置类
@Configuration
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
String host;
@Value("${elasticsearch.port}")
String port;
@Bean
public RestClient restClient() {
int intPort = Integer.parseInt(port);
return RestClient.builder(new HttpHost(host, intPort, "http")).build();
}
@Bean
public ElasticsearchTransport elasticsearchTransport(RestClient restClient) {
return new RestClientTransport(restClient, new JacksonJsonpMapper());
}
@Bean
public ElasticsearchClient elasticsearchClient(ElasticsearchTransport elasticsearchTransport) {
return new ElasticsearchClient(elasticsearchTransport);
}
}准备好测试类
@SpringBootTest
class ElasticsearchDay01ApplicationTests {
@Autowired
ElasticsearchClient elasticsearchClient;
@Test
public void test() {
System.out.println(client);
}
}创建索引
1.添加索引
/**
* 添加索引
* @throws IOException
*/
@Test
public void addIndex() throws IOException {
// 1. 获取专门操作索引的客户端
ElasticsearchIndicesClient indices = elasticsearchClient.indices();
// 2. 调用create方法发起调用
CreateIndexResponse indexResponse = indices.create(request -> request.index("member"));
// 3. 获取操作结果
boolean acknowledged = indexResponse.acknowledged();
System.out.println(acknowledged);
}2.添加索引,并添加映射
/**
* 添加索引,并添加映射
*/
@Test
public void addIndexAndMapping() throws IOException {
// 1. 获取专门操作索引的客户端
ElasticsearchIndicesClient indices = elasticsearchClient.indices();
// 2. 定义mapping
String mappingStr = """
{
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
""";
// 3. 发起创建索引的请求
CreateIndexResponse createIndexResponse = indices.create(request -> request
// 指定索引
.index("member")
// 设置请求中的mapping参数
.mappings(mapping -> mapping.withJson(new StringReader(mappingStr))));
// 4. 获取索引创建结果
Boolean acknowledged = createIndexResponse.acknowledged();
System.out.println(acknowledged);
}
查询、删除、判断索引
查询索引
/**
* 查询索引
*/
@Test
public void queryIndex() throws IOException {
// 1. 获取专门操作索引的客户端
ElasticsearchIndicesClient indices = elasticsearchClient.indices();
// 2. 发起获取索引的请求
GetIndexResponse getIndexResponse = indices.get(request -> request.index("member"));
// 3. 获取查询索引的结果
Map<String, IndexState> result = getIndexResponse.result();
for (String key : result.keySet()) {
System.out.println(key + ": " + result.get(key).mappings().properties());
}
}
删除索引
/**
* 删除索引
*/
@Test
public void deleteIndex() throws IOException {
// 1. 获取专门操作索引的客户端
ElasticsearchIndicesClient indices = elasticsearchClient.indices();
// 2. 发起删除索引的请求
DeleteIndexResponse deleteIndexResponse = indices
// 删除索引
.delete(request -> request.index("member"));
// 3. 获取删除索引的结果
Boolean acknowledged = deleteIndexResponse.acknowledged();
System.out.println(acknowledged);
}索引是否存在
/**
* 索引是否存在
*/
@Test
public void existIndex() throws IOException {
boolean exists = elasticsearchClient.indices()
// 判断索引是否存在
.exists(request -> request.index("member"))
.value();
System.out.println(exists);
}
添加文档
1.添加文档,使用map作为数据
@Test
public void addDoc1() throws IOException {
// 用map对象表示待添加的文档的各个属性的值
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("id", 1);
paramMap.put("name", "xuejia");
paramMap.put("address", "武汉市江岸区");
// 添加文档:指定索引,文档的唯一表示,文档各字段值
Result result = elasticsearchClient.index(request -> request
// 指定索引名称
.index("member")
// 指定文档的唯一标识
.id("cskaoyan001")
// 指定
.document(paramMap))
.result();
System.out.println(result.jsonValue());
}2.添加文档,使用对象作为数据
@Test
public void addDoc2() throws IOException {
// 用对象的成员变量值来表示文档的各个属性值
Member member = new Member();
member.setId(2);
member.setName("shitou");
member.setAddress("武汉市江夏区");
// 将对象转化成Json字符串
String docJson = JSON.toJSONString(member);
// 发起添加文档的请求
Result result = elasticsearchClient.index(request -> request
// 指定添加文档的索引
.index("member")
// 指定所添加的文档的唯一标识
.id("cskaoyan002")
// 以Json的形式指定文档的各个属性值
.withJson(new StringReader(docJson)))
.result();
// 输出添加结果
System.out.println(result.jsonValue());
}修改、查询、删除文档
1.修改文档:添加文档时,如果id存在则修改(全量修改),或者做增量修改
/**
* 修改文档:添加文档时,如果id存在则修改,id不存在则添加
*/
@Test
public void UpdateDoc() throws IOException {
// 将要修改的文档的所有属性值,以key-value的形式放入map
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("id", 1);
paramMap.put("name", "xuejia666");
paramMap.put("address", "武汉市江岸区");
// 发起添加文档的请求(实际效果为全量修改)
Result result = elasticsearchClient.index(request -> request
// 指定添加文档的索引
.index("member")
// 指定待添加的文档的唯一标识
.id("cskaoyan001")
// 指定要修改的文档的各个属性值
.document(paramMap))
.result();
// 输出结果
System.out.println(result.jsonValue());
}
/*
增量修改,只修改文档的一部分
*/
@Test
public void update() throws IOException {
// 仅仅只讲要修改的文档的各个属性值放入map
HashMap<String, Object> updateDocMap = new HashMap<>();
updateDocMap.put("name", "shitou666");
// 发起增量修改的请求,第二个参数表示要修改的各个属性值放在Map中
Result result = elasticsearchClient.update(request -> request
.index("member")
.id("cskaoyan002")
.doc(updateDocMap),
Map.class)
.result();
// 输出结果
System.out.println(result.jsonValue());
}
3.根据id查询文档
/**
* 根据id查询文档
*/
@Test
public void getDoc() throws IOException {
// 发起获取文档的请求, 泛型为map表示文档数据封装在Map中
GetResponse<Map> getResponse = elasticsearchClient.get(request -> request
//
.index("member")
.id("cskaoyan002"),
// Map.class参数表示文档内容封装在Map对象中
Map.class);
Map<String, Object> source = getResponse.source();
System.out.println(source);
}4.根据id删除文档
/**
* 根据id删除文档
*/
@Test
public void delDoc() throws IOException {
String result = elasticsearchClient.delete(request -> request
// 指定索引名称
.index("member")
// 指定要删除的文档的唯一标识
.id("cskaoyan001"))
.result()
.jsonValue();
System.out.println(result);
}Elasticsearch 高级操作
昨天我们学习了,对于Elastic Search基本的索引,映射,文档相关的增删改查操作。但是对于Elastic Search还有一些更为复杂的高级操作。
批量操作
通过批量操作,我们可以一次向Elastic Search发送多条增删改操作。从而达到一定程度上节省带宽的操作
基本语法
- 先来看通过脚本的方式执行批量操作:
# 准备工作定义索引,及其映射
PUT teacher
{
"mappings": {
"properties": {
"id": {"type": "long"},
"name": {"type": "text"},
"age": {"type": "integer"}
}
}
}批量操作脚本
#批量操作
#删除1号
#新增2号
#更新2号
POST _bulk
{"create": {"_index": "teacher", "_id": "2"}}
{"name": "南风", "age": 18}
{"update": {"_index": "teacher", "_id": 2}}
{"doc": {"name":"景天", "age": 19}}
{"delete": {"_index":"teacher", "_id": "1"}}- 接着我们使用JAVA API执行批量操作
/**
* Bulk 批量操作
*/
@Test
public void test2() throws IOException {
// 准备待添加的第一条文档的各个字段值
HashMap<String, Object> firstDocMap = new HashMap<>();
firstDocMap.put("id", 1);
firstDocMap.put("name", "xuejia");
firstDocMap.put("age", 18);
// 准备待添加的第二条文档的各个字段值
HashMap<String, Object> secondDocMap = new HashMap<>();
secondDocMap.put("id", 2);
secondDocMap.put("name", "shitou");
secondDocMap.put("age", 19);
// 准备待添加的第二条文档的各个字段值
HashMap<String, Object> updateMap = new HashMap<>();
updateMap.put("name", "xuejia666");
updateMap.put("id", 100);
// 调用bulk方法执行批量操作
BulkResponse bulkResponse = elasticsearchClient.bulk(request -> request
/*
1. 调用operations方法构造一次操作
2. 使用operations方法参数来构造一个具体操作,调用index方法构造添加文档操作
*/
.operations(operation -> operation.index(index -> index
.index("teacher")
.id("cskaoyan001")
.document(firstDocMap)))
/*
1. 调用operations方法构造一次操作
2. 使用operations方法参数来构造一个具体操作,调用index方法构造添加文档操作
*/
.operations(operation -> operation.index(index -> index
.index("teacher")
.id("cskaoyan002")
.document(secondDocMap)))
/*
1. 调用operations方法构造一次操作
2. 使用operations方法参数来构造一个具体操作,调用update方法构造文档的
增量更新操作
*/
.operations(operation -> operation.update(update -> update
.index("teacher")
.id("cskaoyan001")
.action(action -> action.doc(updateMap))))
/*
1. 调用operations方法构造一次操作
2. 使用operations方法参数来构造一个具体操作,调用delete方法构造删除文档操作
*/
.operations(operation -> operation.delete(delete -> delete
.index("teacher")
.id("cskaoyan002"))));
// 输出批量操作的中的错误信息(如果有的话)
System.out.println(bulkResponse.errors());
}批量从数据库导入数据
- 创建索引和映射
PUT product
{
"mappings": {
"properties": {
"id":{"type": "long"},
"image": {"type": "keyword"},
"status": {"type": "integer"},
"sellPoint": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"num":{"type": "integer"},
"tmName": {"type": "keyword"},
"cid": {"type": "long"},
"price": {"type": "double"},
"limitNum": {"type": "integer"},
"created": {"type": "date"},
"updated": {"type": "date"}
}
}
}- 代码实现从数据库批量将数据导入Elastic Search
/**
* 从Mysql 批量导入 elasticSearch
*/
@Test
public void test3() throws IOException {
List<Item> items = itemMapper.selectList(null);
BulkResponse bulkResponse = elasticsearchClient.bulk(request -> {
for (Item item : items) {
String docJson = JSON.toJSONString(item);
System.out.println(docJson);
// 针对每一个item对象,构造一个添加文档的操作,添加到批量操作请求中
request.operations(operation -> operation.index(index -> index
.index("product")
.id(item.getId().toString())
.document(item)));
}
return request;
});
// 输出批量操作的中的错误信息(如果有的话)
System.out.println(bulkResponse.errors());
}高级查询
match all 查询
match all查询,相当于不加查询条件的查询索引中所有的文档
GET product/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 100
}/**
* 查询所有
* 1. matchAll
* 2. 将查询结果封装为Goods对象,装载到List中
* 3. 分页。默认显示10条
*/
@Test
public void matchAll() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 构造match_all查询
.query(query -> query.matchAll(matchAll -> matchAll))
// 设置from
.from(0)
// 设置size
.size(30), Item.class);
// 获取响应的hits属性值
HitsMetadata<Item> searchHits = searchResponse.hits();
// 获取满足查询条件的总的文档条数
long totalCount = searchHits.total().value();
System.out.println("totalCount: " + totalCount);
// 获取响应的hits属性的hits属性值(包含查询到的每条文档信息)
List<Hit<Item>> hits = searchHits.hits();
ArrayList<Item> items = new ArrayList<>();
for (Hit<Item> hit : hits) {
// 获取source属性值,代表原始文档
Item source = hit.source();
items.add(source);
}
System.out.println(items);
}term 查询
term查询和字段类型有关系,首先回顾一下ElasticSearch两个数据类型
ElasticSearch两个数据类型:
- text:会分词,不支持聚合
- keyword:不会分词,将全部内容作为一个词条,支持聚合
term查询:不会对查询条件进行分词。但是注意,term查询,查询text类型字段时,文档中类型为text类型的字段本身仍然会分词
GET product/_search
{
"query": {
"term": {
"title": {
"value": "手机充电器"
}
}
}
}Java API
@Test
public void testTerm() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 构造term查询
.query(query -> query.term(term -> term
.field("title")
.value("手机充电器"))), Item.class);
// 获取响应的hits属性值
HitsMetadata<Item> searchHits = searchResponse.hits();
// 获取满足查询条件的总的文档条数
long totalCount = searchHits.total().value();
System.out.println("totalCount: " + totalCount);
// 获取响应的hits属性的hits属性值(包含查询到的每条文档信息)
List<Hit<Item>> hits = searchHits.hits();
ArrayList<Item> items = new ArrayList<>();
for (Hit<Item> hit : hits) {
// 获取source属性值,代表原始文档
Item source = hit.source();
items.add(source);
}
System.out.println(items);
}match查询
match查询的特征:
•会对查询条件进行分词。
•然后将分词后的查询条件和目标字段分词后的词条进行等值匹配
•默认取并集(OR),即只要查询条件中的一个分词和目标字段值的一个分词(词条)匹配,即认为匹配查询条件
# match查询
GET product/_search
{
"query": {
"match": {
"title": "手机充电器"
}
},
"size": 500
}match 的默认搜索(or 并集)例如:华为手机,会分词为 “华为”,“手机” 只要出现其中一个词条都会认为词条匹配
match的 and(交集) 搜索,例如:例如:华为手机,会分词为 “华为”,“手机” 但要求“华为”,和“手机”同时出现在词条中,才算词条匹配
GET product/_search
{
"query": {
"match": {
"title": {
"query": "手机充电器",
"operator": "and"
}
}
},
"size": 500
}Java API
@Test
public void testMatch() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 构造match查询
.query(query -> query.match(match -> match
.field("title")
.query("手机充电器")
//.operator(Operator.And)
)), Item.class);
// 获取响应的hits属性值
HitsMetadata<Item> searchHits = searchResponse.hits();
// 获取满足查询条件的总的文档条数
long totalCount = searchHits.total().value();
System.out.println("totalCount: " + totalCount);
// 获取响应的hits属性的hits属性值(包含查询到的每条文档信息)
List<Hit<Item>> hits = searchHits.hits();
ArrayList<Item> items = new ArrayList<>();
for (Hit<Item> hit : hits) {
// 获取source属性值,代表原始文档
Item source = hit.source();
items.add(source);
}
System.out.println(items);
}querystring
queryString 多条件查询
- 会对查询条件进行分词。
- 然后将分词后的查询条件和词条进行等值匹配
- 默认取并集(OR)
- 可以指定多个查询字段
query_string:可以识别query中的连接符(or 、and)
# queryString
GET product/_search
{
"query": {
"query_string": {
"fields": ["title","sellPoint"],
"query": "原装充电器"
}
}
}
GET product/_search
{
"query": {
"query_string": {
"fields": ["title","sellPoint"],
"query": "原装 AND 充电器"
}
}
}java代码
public void queryStringQuery() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 构造query_string查询
.query(query -> query.queryString(queryString -> queryString
// 设置fields
.fields("title", "sellPoint")
// 设置查询关键词
.query("原装充电器")
//.query("原装 AND 充电器")
)), Item.class);
// 获取响应的hits属性值
HitsMetadata<Item> searchHits = searchResponse.hits();
// 获取满足查询条件的总的文档条数
long totalCount = searchHits.total().value();
System.out.println("totalCount: " + totalCount);
// 获取响应的hits属性的hits属性值(包含查询到的每条文档信息)
List<Hit<Item>> hits = searchHits.hits();
ArrayList<Item> items = new ArrayList<>();
for (Hit<Item> hit : hits) {
// 获取source属性值,代表原始文档
Item source = hit.source();
items.add(source);
}
System.out.println(items);
}范围 & 排序查询
GET product/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 1000
}
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 构造range查询
.query(query -> query.range(range -> range
.number(number -> number
// 设置查询字段
.field("price")
// 设置下限
.gte(100.0)
// 设置上限
.lte(3000.0))))
// 构造排序
.sort(sort -> sort.field(field -> field
// 指定排序字段
.field("price")
// 指定排序方式
.order(SortOrder.Desc)))
, Item.class);
// 获取响应的hits属性值
HitsMetadata<Item> searchHits = searchResponse.hits();
// 获取满足查询条件的总的文档条数
long totalCount = searchHits.total().value();
System.out.println("totalCount: " + totalCount);
// 获取响应的hits属性的hits属性值(包含查询到的每条文档信息)
List<Hit<Item>> hits = searchHits.hits();
ArrayList<Item> items = new ArrayList<>();
for (Hit<Item> hit : hits) {
// 获取source属性值,代表原始文档
Item source = hit.source();
items.add(source);
}
System.out.println(items);复合查询 bool
boolQuery:对多个查询条件连接。其组成主要分为如下四个部分:
- must(and):条件必须成立
- must_not(not):条件必须不成立
- should(or):条件可以成立
- filter:条件必须成立,性能比must高。不会计算得分
# must
GET product/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": {
"value": "充电器"
}
}
},
{
"match": {
"sellPoint": "快充"
}
}
]
}
}
}
# must_not
GET product/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"title": "充电器"
}
}
]
}
}
}# should 中的多个条件是or关系
GET product/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "充电器"
}
}
},
{
"term": {
"sellPoint": {
"value": "小菜鸡"
}
}
}
]
}
}
}# filter
GET product/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"title": {
"value": "充电器"
}
}
},
{
"match": {
"sellPoint": "快充"
}
}
]
}
}
}这里有几点需要注意:
- 一个复合查询中,可以同时包含must,must not,should,filter中的一个或多个部分
- 每一部分,都可以包含多个查询条件(should中的多个查询条件是or关系)
- 当存在must,或者filter的时候,should中的条件默认不生效
- must和filter都可以表示同时满足多个条件的查询,但是不同的地方在于must会计算文档的近似度得分,filter不会(must_not也不会)
# boolquery 包含多个部分
GET product/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": {
"value": "充电器"
}
}
}
],
"filter":[
{
"term": {
"title": "原装"
}
},
{
"range":{
"price": {
"gte": 40,
"lte": 100
}
}
}
]
}
}
}
JAVA API:
布尔查询:boolQuery
- 查询商品为(title): 充电器
- 查询过滤条件:原装
- 查询价格在:40-100
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 构造bool查询
.query(query -> query.bool(bool -> bool
// 构造must部分
.must(must -> must.match(match -> match
// 设置match查询的字段
.field("title")
// 设置查询关键词
.query("充电器")))
// 构造should部分
.should(should -> should.term(term -> term
// 设置term查询的字段
.field("title")
// 设置查询关键词
.value("原装")))
// 构造filter部分
.filter(filter -> filter.range(range -> range
.number(number -> number
// 设置range查询的字段
.field("price")
// 设置range查询的上限
.gte(100.0)
// 设置range查询的下限
.lte(3000.0))))))
, Item.class);
// 获取响应的hits属性值
HitsMetadata<Item> searchHits = searchResponse.hits();
// 获取满足查询条件的总的文档条数
long totalCount = searchHits.total().value();
System.out.println("totalCount: " + totalCount);
// 获取响应的hits属性的hits属性值(包含查询到的每条文档信息)
List<Hit<Item>> hits = searchHits.hits();
ArrayList<Item> items = new ArrayList<>();
for (Hit<Item> hit : hits) {
// 获取source属性值,代表原始文档
Item source = hit.source();
items.add(source);
}
System.out.println(items);聚合
聚合查询分为两种类型:
- 指标聚合:相当于MySQL的聚合函数。max、min、avg、sum等
- 桶聚合:相当于MySQL的 group by 操作。不要对text类型的数据进行分组,会失败。
# 聚合查询
# 指标聚合 聚合函数
GET product/_search
{
"query": {
"match": {
"title": "耳机"
}
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
# 桶聚合 分组
GET product/_search
{
"query": {
"match": {
"title": "充电器"
}
},
"aggs": {
"price_bucket": {
"terms": {
"field": "price"
}
}
}
}JAVA API
// 测试最大指标值聚合
@Test
public void testValueAgg() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 设置size为0的目的是不返回查询结果
.size(0)
// 构造最大指标值聚合,首先指定聚合名称
.aggregations("max_price"
, aggregation -> aggregation
// 指定指标值聚合类型(类型通过方法名指定)和字段
.max(max -> max.field("price")))
, Item.class);
// 获取响应中的aggregations属性的值
Map<String, Aggregate> aggregations = searchResponse.aggregations();
// 根据聚合操作的名称获取聚合操作的结果
Aggregate aggregate = aggregations.get("max_price");
// 获取最大指标值聚合的结果
MaxAggregate max = aggregate.max();
// 获取最大指标值
double maxPrice = max.value();
System.out.println(maxPrice);
}
public void bucketAggs() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("product")
// 不返回查询结果
.size(0)
// 构造分桶聚合,首先指定聚合名称
.aggregations("price_bucket"
, aggregation -> aggregation
// 指定指标值聚合类型(类型通过方法名指定)和字段
.terms(terms -> terms.field("price"))), Item.class);
// 获取响应中的aggregations属性的值
Map<String, Aggregate> aggregations = searchResponse.aggregations();
// 根据聚合操作的名称获取聚合操作的结果
Aggregate tmNameGroup = aggregations.get("price_bucket");
// 获取分桶聚合的结果
StringTermsAggregate sterms = tmNameGroup.sterms();
// 获取分桶集合
List<StringTermsBucket> buckets = sterms.buckets().array();
// 遍历分桶集合
for (StringTermsBucket bucket : buckets) {
System.out.println(bucket.key().stringValue() + ":" + bucket.docCount());
}
}地理位置查询
我们知道地球上的每一个点都是可以用经纬度来标识的,因此我们可以根据对经纬度坐标的查询实现地理位置查询。
在ES中有专门的数据类型来表示经纬度: geo_point, 它包含经度和维度两个值。
PUT locations
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"location": {
"type": "geo_point"
},
"category": {
"type": "keyword"
}
}
}
}可以使用如下两种方式在添加文档时,指定文档的geo_point类型field值
POST /locations/_doc/11
{
"name": "北京大学",
"location": "39.9925,116.3053", // 字符串格式:纬度,经度
"category": "education"
}POST /locations/_doc/12
{
"name": "清华大学",
"location": [116.3304, 40.0000], // 数组格式:[经度,纬度]
"category": "education"
}接下来为了方便测试,我们使用批量查询项索引中添加一些数据:
POST _bulk
{"create": {"_index": "locations", "_id": "1"}}
{"name": "天安门广场", "location": "39.9078,116.3974", "category": "landmark"}
{"create": {"_index": "locations", "_id": "2"}}
{"name": "故宫", "location": "39.9163,116.3971", "category": "landmark"}
{"create": {"_index": "locations", "_id": "3"}}
{"name": "颐和园", "location": "39.9999,116.2754", "category": "park"}
{"create": {"_index": "locations", "_id": "4"}}
{"name": "北京动物园", "location": "39.9378,116.3333", "category": "park"}
{"create": {"_index": "locations", "_id": "5"}}
{"name": "奥林匹克公园", "location": "39.9929,116.3963", "category": "park"}
{"create": {"_index": "locations", "_id": "6"}}
{"name": "三里屯", "location": "39.9333,116.4531", "category": "shopping"}
{"create": {"_index": "locations", "_id": "7"}}
{"name": "王府井", "location": "39.9086,116.4094", "category": "shopping"}
{"create": {"_index": "locations", "_id": "8"}}
{"name": "中关村", "location": "39.9833,116.3167", "category": "business"}
{"create": {"_index": "locations", "_id": "9"}}
{"name": "国贸", "location": "39.9097,116.4581", "category": "business"}
{"create": {"_index": "locations", "_id": "10"}}
{"name": "首都机场", "location": "40.0799,116.6031", "category": "transport"}矩形区域内的点
查询类型为: geo_bounding_box
查询字段:location
查询需要制定两个参数:
- top_left: 矩形左上角的点坐标
- bottom_right: 矩形右下角的点的坐标
注意,坐标的表示方式可以是字符串,也可以是数组(注意不同方式的经纬度书写顺序)
# 查询北京二环内的地点
GET locations/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": "39.95,116.35",
"bottom_right": "39.89,116.45"
}
}
}
}对应的查询代码
@Test
public void geoBoxingTest() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Item> searchResponse = elasticsearchClient.search(request -> request
// 指定索引
.index("locations")
// 构造geo_bounding_box查询
.query(query -> query.geoBoundingBox(geo -> geo
// 指定查询字段
.field("location")
// 指定top_left和bottom_right参数
.boundingBox(box -> box.tlbr(tlbr -> tlbr
// 构造top_left
.topLeft(GeoLocation.of(location -> location.latlon(v -> v.lat(39.95).lon(116.35))))
// 构造bottom_right
.bottomRight(GeoLocation.of(location -> location.latlon(v -> v.lat(39.89).lon(116.45))))))))
, Item.class);
long totalCount = searchResponse.hits().total().value();
System.out.println("totalCount: " + totalCount);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(JSON.toJSONString(hit.source()));
}
}距离查询
我们还可以查询距离某个中心点一定距离范围内的所有点。距离查询语法如下:
查询类型: geo_distance
中心点: location
距离计算方式: 1) arc 计算球面距离(精确) 2)plain 计算平面距离(精度低但是快)
GET locations/_search
{
"query": {
"geo_distance": {
"distance": "2km", // 距离值+单位
"location": "39.9,116.4", // 中心点
"distance_type": "plain" // 计算方式
}
}
}对应的java代码
@Test
public void geoDistanceTest() throws IOException {
// 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Map> searchResponse = elasticsearchClient.search(request -> request
// 设置索引
.index("locations")
// 构造geo_distance查询
.query(query -> query.geoDistance(geoDistance -> geoDistance
// 指定查询字段
.field("location")
// 指定中心坐标
.location(GeoLocation.of(geoLocation -> geoLocation.latlon(v -> v.lat(39.9).lon(116.4))))
// 指定插叙凝聚力
.distance("2km")
// 指定距离的计算方式
.distanceType(GeoDistanceType.Arc)))
, Map.class);
long totalCount = searchResponse.hits().total().value();
System.out.println("totalCount: " + totalCount);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(JSON.toJSONString(hit.source()));
}
}除了距离查询之外,我们还可以根据距离中心点的距离排序
排序方式: _geo_distance
中心点: location
距离单位: unit
计算方式: distance_type
GET locations/_search
{
"query": {
"bool": {
"must": [
{"term": {"category": "park"}}
],
"filter": {
"geo_distance": {
"distance": "20km",
"location": "39.9078,116.3974"
}
}
}
},
"sort": [
{
"_geo_distance": {
"location": "39.9078,116.3974",
"order": "asc",
"unit": "km",
"distance_type": "arc"
}
}
]
}| 单位 | 缩写 | 示例 |
|---|---|---|
| 米 | m | “100m” |
| 千米 | km | “5km” |
| 英里 | mi | “3mi” |
| 码 | yd | “500yd” |
| 英尺 | ft | “1000ft” |
| 海里 | nmi | “1nmi” |
对应的java代码
@Test
public void distanceSort() throws IOException {
// // 调用search方法发送查询请求,通过search方法的参数来构造这个请求
SearchResponse<Map> searchResponse = elasticsearchClient.search(request -> request
// 设置索引
.index("locations")
// 构造match_all查询
.query(query -> query.matchAll(matchAll -> matchAll))
// 构造geo_distance排序
.sort(sort -> sort.geoDistance(geoDistanceSort -> geoDistanceSort
// 设置排序字段
.field("location")
// 设置距离中心点
.location(GeoLocation.of(geoLocation -> geoLocation.latlon(v -> v.lat(39.9078).lon(116.3974))))
// 设置距离计算方式
.distanceType(GeoDistanceType.Arc)
// 设置距离单位
.unit(DistanceUnit.Kilometers)
// 设置排序方式
.order(SortOrder.Asc)))
, Map.class);
long totalCount = searchResponse.hits().total().value();
System.out.println("totalCount: " + totalCount);
for (Hit<Map> hit : searchResponse.hits().hits()) {
System.out.println(JSON.toJSONString(hit.source()));
}
}通用写法
以上的各种查询,排序,聚合,其实都可以用一种统一的写法来完成
// 写好dsl脚本,可以包含查询,排序,聚合
String dsl = """
{
"query": {"match_all": {}},
"sort": [
{
"_geo_distance": {
"location": {"lat": 39.9078, "lon": 116.3974},
"order": "desc",
"unit": "km",
"distance_type": "arc"
}
}
]
}
""";
// 调用search方法发起查询请求,利用search方法的第一个参数构造具体查询,第二个参数指定封装文档的对象类型
SearchResponse<Map> searchResponse = elasticsearchClient.search(request -> request
// 指定索引名称
.index("product")
// 指定实际查询执行的dsl脚本, Map.class指定封装文档的对象类型,当然Map可以替换为具体的对象类型
.withJson(new StringReader(dsl)), Map.class);
// 解析结果即可
集群相关知识
我们启动的一个Elasticsearch进程,我们称之为为一个Elasticsearch节点(Node),多个Elasticsearch节点,可以组成一个Elasticsearch集群,接下来,我们就来了解下Elasticsearch集群相关的知识
索引在集群中的分布
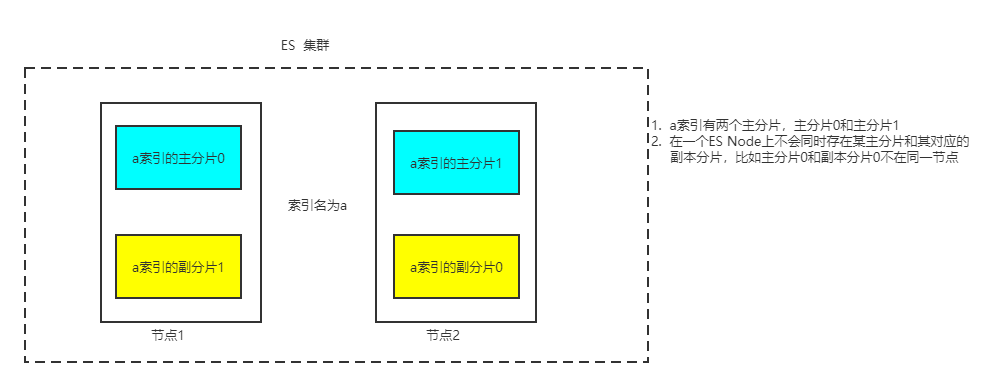
无论是单机还是集群模式,ES中的索引数据都是以分片的形式存在的,一个索引的一个分片中只存储该索引中的一部分数据,即一个索引中的文档数据,被存储在其所属的若干个分片中,每个分片只存储索引部分数据。
对于一个索引所包含的所有分片,又被分成了两种:
- 主分片:一个索引中的文档到底被被分成几部分来存储,主要看索引到底包含多少个主分片,有多少个主分片,索引数据数据就被分成几部分分别存储在主分片中。用户插入ES的文档数据都是首先存储到主分片的。
- 副本分片:而副本分片主要是作为主分片的数据副本而存在,每个主分片都可以有对应的副本分片。
所以,在ES集群中,一个索引的多个分片数据,就保存在不同的ES服务器实例或者说不同的ES Node上,一个单机版的ES服务器,也可以看做是只包含一个ES Node的ES集群,所以一个ES Node可以包含索引的多个分片数据。
这里还有三点细节需要注意:
- ES 不允许将一个主分片和它对应的副本分片存储在同一个ES Node中。这主要是为了防止,一个ES Node 宕机导致,某分片数据全部丢失(主分片和该主分片对应的副本分片的数据全部丢失)。这是因为如果每个主分片至少有一个副本分片,那么即使该主分片所在的ES Node宕机也没关系,ES会自动将其副本分片变为主分片,保证数据的正常访问。
- 一个ES的索引由一个或多个主分片以及零个或多个副本分片构成,即ES不强制要求主分片一定有对应的副本分片
- 在创建索引的时候就可以定义,索引的主分片数量,以及每个主分片对应的副本分片的数量,但是对于一个索引而言,一旦索引创建完毕,其主分片数量就不能在变了,只能修改其副本分片的数量
文档数据在ES集群中的存储和搜索
我们先来看看文档数据的存储:
- 当存储或一篇文档的时候,ES首先根据文档ID的散列值,选择一个主分片,并将该文档发送到该主分片保存。
- 然后,该文档被发送到主分片对应的所有的副本分片进行保存,这使得副本分片和主分片之间保持数据同步
- 数据同步使得副本分片可以服务与搜索请求,并在原有主分片无法访问时自动升级为主分片
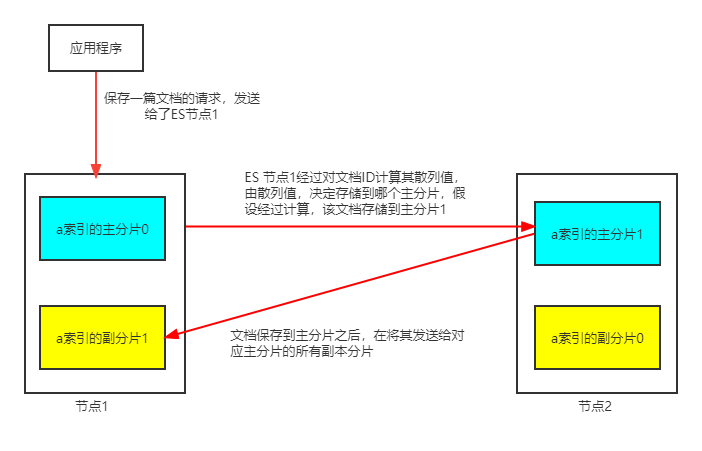
在保存一篇文档的时候,我们讲解了如何决定一篇文档所在的分片的,这一过程我们称为文档路由。当ES散列文档ID时就会发生文档的路由,来决定文档应该索引到哪个分片中
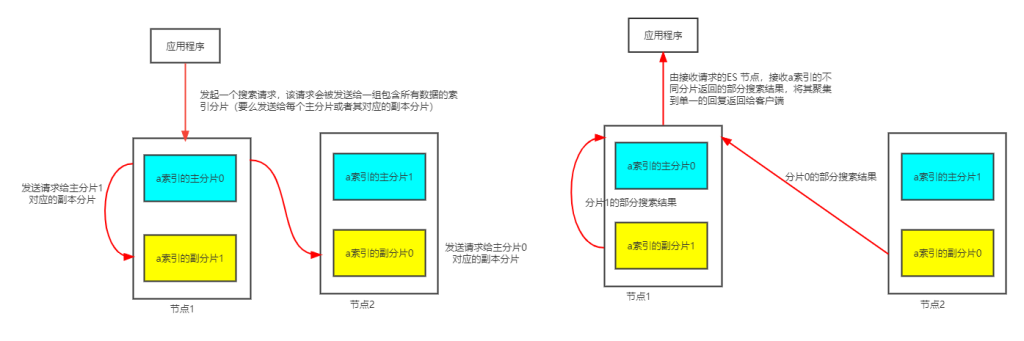
再来看看在集群中搜索文档数据的过程,当在索引中搜索的时候,Elastic Search会在索引的所有分片中进行查找,这些分片可以是主分片,也可以是副本分片,原因是主分片和副本分片通常包含一样的文档。ES在索引的主分片和副本分片中进行搜索请求的负载均衡,使得副本分片对于搜索的性能和容错都有帮助。下面看看具体的搜索过程:
- 搜索请求首先被一个ES Node接收,并将请求转发到一组包含所有数据的索引分片
- 在选择转发请求的分片时,使用轮训算法选择可用分片(这里轮训的是某主分片和其对应的副本分片,并且对于索引中的每一个主分片与其对应的副本分片都会有这样的轮训选择过程),并将搜索请求转发到所有选中的分片,
- 然后,ES将从这些接收到请求的分片收集搜索的结果,将其聚集到单一的回复,然后将回复返回给客户端
脑裂问题
在一个ES集群中,包含多个ES Node,这多个ES Node又可以扮演不同的角色,实现不同的功能,主要有以下几种角色:
- Matster Node:负责创建,删除索引,以及给节点分配分片等集群管理的共工作
- Data Node: 负责存储文档数据,以及对文档数据的CRUD操作
- Coordinating Node: 负责接收客户端的请求,并将请求分发到各个相关节点,并最终收集各节点返回的结果,整合为一个统一的结果,返回给客户端, 其实每个ES Node都隐式的扮演者协调节点的角色。
在这其中,Data Node和Coordinating Node都可以有多个,但是Matster Node作为管理集群的”大脑”。正常情况下,当主节点无法工作时,会从备选主节点中选举一个出来变成新主节点,原主节点回归后变成备选主节点
但有时因为网络抖动等原因,主节点没能及时响应,集群误以为主节点挂了,选举了一个新主节点,此时一个es集群中有了两个主节点,其他节点不知道该听谁的调度,结果将是灾难性的!这种类似一个人得了精神分裂症,就被称之为“脑裂”现象。
之所以产生脑裂问题的原因是主节点因为各种原因,在收到请求后未能及时响应,导致主节点未能及时响应的原因,一般主要有以下几点:
- 网络抖动
内网一般不会出现es集群的脑裂问题,可以监控内网流量状态。外网的网络出现问题的可能性大些
- 节点负载
如果主节点同时承担数据节点的工作,可能会因为工作负载大而导致对应的 ES 实例停止响。
- 内存回收(STW:stop the world)
由于数据节点上es进程占用的内存较大,较大规模的内存回收操作也能造成es进程失去响应。
如何解决脑裂问题呢?
- 不要把主节点同时设为数据节点(node.master=true和node.data不要同时设为true),node.master=true意味着该节点有竞选Master Node的资格,node.date=true,意味着该节点扮演数据节点的角色
- 将节点响应超时(discovery.zen.ping_timeout)稍稍设置长一些(默认是3秒),避免误判。
- 设置需要超过半数的备选节点同意,才能发生主节点重选,类似需要参议院半数以上通过,才能弹劾现任总统。(discovery.zen.minimum_master_nodes = 半数以上的投票节点数)。添加了一条选举规则: 大部分人(超过半数)选举1个node为masterNode,这个节点才能成为masterNode